By Andrea Leccese
January 13th, 2019
Executive Summary
Recently there has been much development and interest in machine learning, with the most promising results in speech and image recognition. This research paper analyzes the performance of a deep learning method, long short-term memory neural networks (LSTM’s), applied to the US stock market as represented by the S&P 500. The paper shows that, while this technique may have had good success in other fields like speech recognition, it does not perform as well when applied to financial data. They are in fact characterized by high noise-to-signal ratio, which makes it difficult for a machine learning model to find patterns and predict future prices.
This research article is structured as follows. The first section introduces LSTM’s and why they may be applied to financial time series. The second section analyzes the performance of an LSTM applied to the S&P 500. The third section concludes.
1. What is an LSTM?
Long short-term memory (LSTM) neural networks are a particular type of deep learning model. In particular, it is a type of recurrent neural network that can learn long-term dependencies in data, and so it is usually used for time-series predictions.
Figure 1 shows the architecture of an LSTM layer.
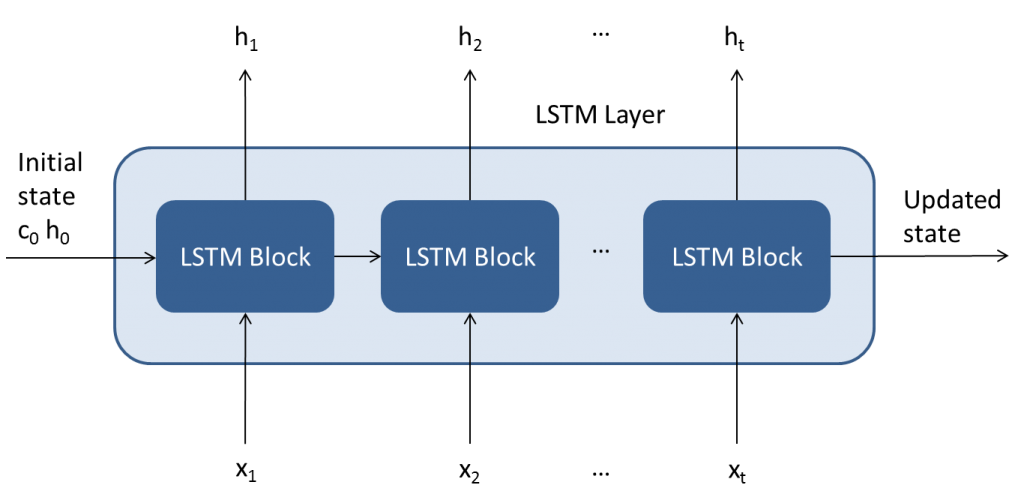
As the figure shows, it is composed of a repeating core module. This structure makes the LSTM capable of learning long-term dependencies. The first LSTM block takes the initial state of the network and the first time step of the sequence X1, and computes the first output h1 and the updated cell state c1. At time step t, the block takes the current state of the network (ct−1, ht−1) and the next time step of the sequence Xt, and computes the output ht and the updated cell state ct.
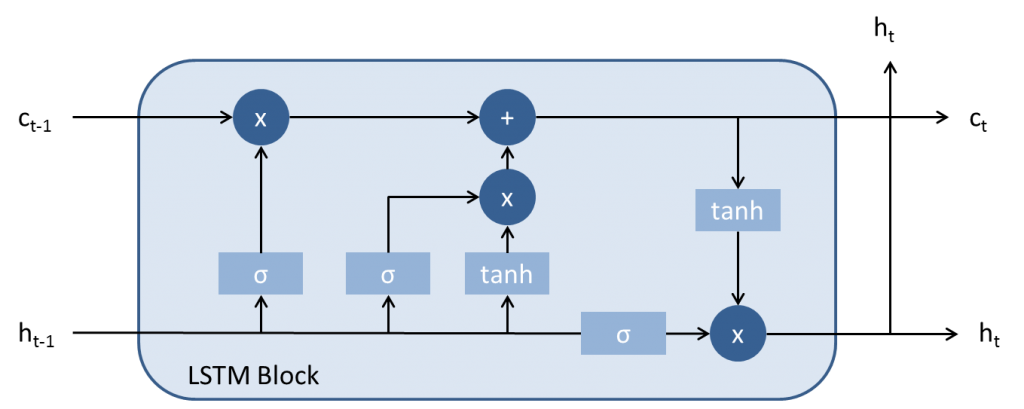
Figure 2 shows the architecture of an LSTM block, which is composed of 4 main components:
- Input gate: it controls the level of cell state update
- Forget gate: it controls the level of cell state reset
- Cell candidate: add information to the cell state
- Output gate: it controls the level of cell state added to the hidden gate.
In order to learn the features of the modeled task and be able to predict, an LSTM needs to be trained. This process consists in computing the weights and biases of the LSTM by minimizing an objective function, typically RMSE, through some optimization algorithms. Once the model it’s trained on an initial training dataset and validated on a validation set, it is then tested on a real out of sample testing. This ensures that the model did in fact learn useful features and it is not overfitted on the training set, with poor prediction capabilities on new data. The next section analyses the performance of an LSTM applied to the S&P 500.
2. Performance LSTM applied to the US equity market
The used dataset is composed of closing daily prices for the US stock market, as represented by the S&P 500, from January 3, 1950 to January 4, 2019, for a total number of 17,364 observations. The data is divided in 60% for training, 20% for validation, and 20% for testing.
Figure 3 shows the data used for the analysis on a log scale.
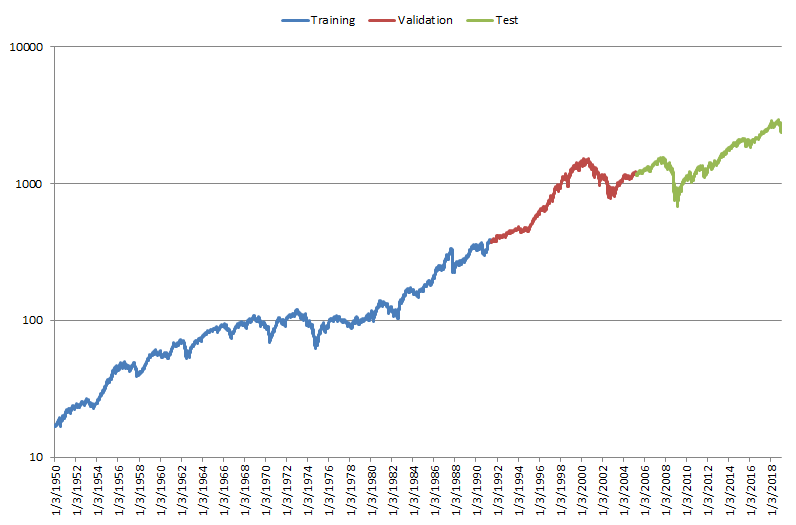
In our analysis we trained an LSTM neural network composed of 1 hidden layer, 20 neurons, and time series length of 20 values. We tried different combinations for the neural network parameters and architectures and found similar results.
Figure 4 shows the actual prices compared to the next day values predicted by the trained LSTM.
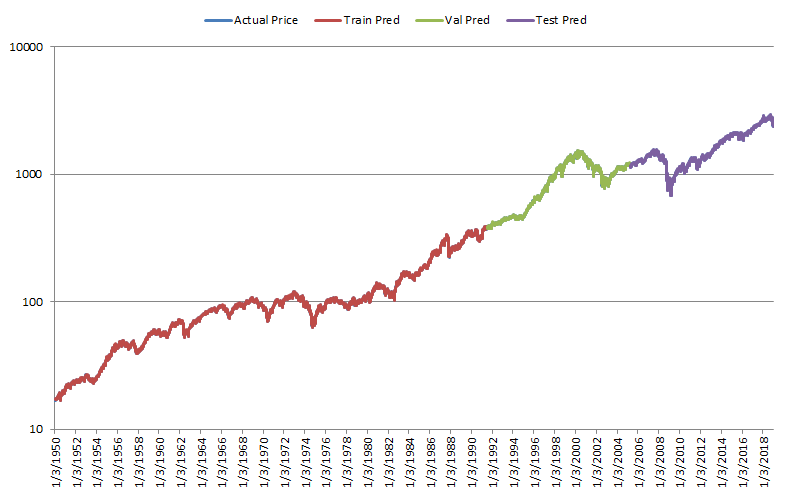
As it can be seen from the figure, the predicted values are very close to the actual prices, so that the underlying actual price cannot be seen properly. Thus, it may seem that the LSTM does a good job at predicting the next value for the time series under consideration.
Table 1 reports the performance stats for the LSTM accuracy in predicting the next day price.
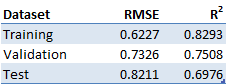
This data corroborates what we can see from Figure 4. The low values in RMSE and decent values in R2 show that the LSTM may be good at predicting the next values for the time series in consideration.
Figure 5 shows a sample of 100 actual prices compared to predicted ones, from August 13, 2018 to January 4, 2019.
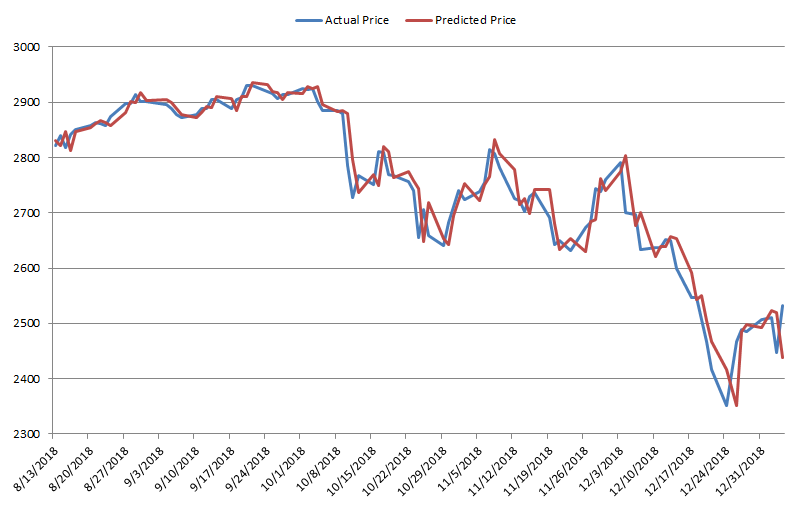
This figure makes us draw a different conclusion. While in aggregate it seemed that the LSTM is effective at predicting the next day values, in reality the prediction made for the next day is very close to the actual value of the previous day. This can be further seen by Figure 6, which shows the actual prices lagged by 1 day compared to the predicted price.
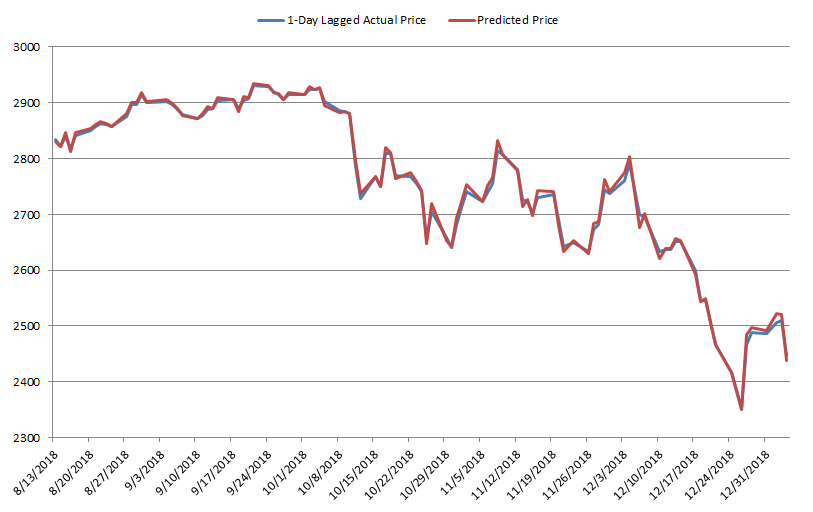
As the figure shows, the 2 series are almost identical, confirming our previous conclusions.
These results demonstrate that LSTM is not able to predict the value for the next day in the stock market. In fact, the best guess the model can make is a value almost identical to the current day’s price.
3. Conclusion
While it is true that new machine learning algorithms, in particular deep learning, have been quite successful in different areas, they are not able to predict the US equity market. As demonstrated by the previous analyses, LSTM just use a value very close to the previous day closing price as prediction for the next day value. This is what would be expected by a model that has no predictive ability.
This also highlights that while some machine learning techniques may be useful in finance, quantitative hedge funds must take another route and come up with strategies capable of delivering alpha for their clients.
Subscribe to our newsletter to receive our latest insights in quantitative investment management. For more info about our investment products, send us an email at info@blueskycapitalmanagement.com or fill out our info request form.